Ricardo, estudiante de Ingeniería Electrónica en UTEC, ha participado en diversos proyectos dentro y fuera de la universidad y culminó su tesis con un proyecto colaborativo entre la Universidad de Yale, la Universidad de Lund, y la UTEC, recibiendo con honores su titulación. Conoce a detalle su experiencia.
1. ¿Cómo ha sido tu experiencia académica en la UTEC?
Mi trayectoria universitaria en la carrera de ingeniería electrónica de la UTEC ha sido una experiencia bastante enriquecedora con diversos desafíos de por medio, un extraordinario soporte del profesorado, y un gratificante crecimiento exponencial. Elegí esta universidad desde un comienzo por su excelente gama de oportunidades y por fomentar la ingeniería desde el primer día con un visionario plan de estudios. Estas expectativas iniciales fueron gratamente sobrepasadas. Logré viajar por el mundo muchas veces mientras recibía una formación de primera. Al término de este camino, me siento muy agradecido por recibir en mi tesis de titulación el primer reconocimiento con honores dándole un memorable fin a mi época universitaria.
2. ¿Qué proyectos de ingeniería realizaste durante tu trayectoria académica?
Esta carrera me atrajo en un principio por la capacidad de resolver problemas reales utilizando la tecnología electrónica de manera genérica. Pasé desde el campo de procesamiento de señales biomédicas, a purificación de agua con sistemas electrónicos, hasta generación de energía vía reacciones electroquímicas. Gracias a la guía ejemplar de cada profesor encargado, con el proyecto del primer campo obtuve el tercer puesto a la mejor investigación en un congreso nacional de IEEE, el segundo me permitió viajar a la Universidad de Harvard por una escuela de verano y a Colorado School of Mines por un semestre de intercambio, y el último me llevó a una competencia de ChemCar en Alemania. Cada experiencia me enseñó mucho, no solo por la temática, sino también por ampliar mi panorama e ir descubriendo mi especialización preferida con hitos significativos en mi formación.

Proyectos de ingeniería presentados en INTERCON, Universidad de Harvard, Colorado School of Mines, y ChemCar Wettbewerb.
3. ¿Cómo elegiste tu campo de especialización?
Tras pasar por una fase exploratoria, la electrónica aplicada en la medicina comenzó a atraerme en gran medida. A través del programa REPU, realicé una pasantía de investigación en dispositivos microfluídicos en la Universidad de Yale. Apoyé en un proyecto doctoral que buscaba reducir los tiempos de diagnóstico de tuberculosis al separar y contar las bacterias con fenómenos electrocinéticos. Luego, mediante el programa ELAP, en la Universidad de Alberta continué con el mismo proyecto realizando ensayos de impedancia en estos dispositivos microfluídicos. Por medio de esta exposición inicial a la microfabricación, detección de parámetros biofísicos, análisis de datos, pude profundizar mi entendimiento del estado de los sistemas biológicos vía fenómenos eléctricos.
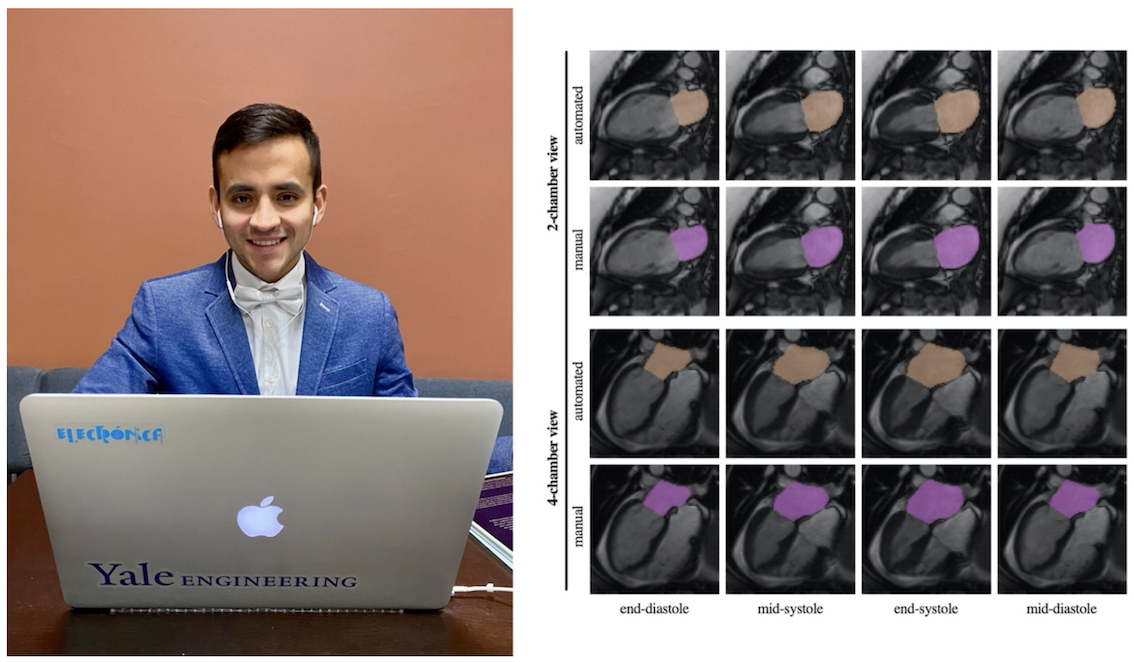
Después de explorar diversas herramientas de ingeniería electrónica aplicadas al campo biomédico, creció un interés especial por las imágenes médicas por resonancia magnética cardiovascular debido al impacto que podría tener en el diagnóstico y tratamiento de muchos pacientes. Esta vez, tuve la dicha de estar en el momento indicado para entrar al grupo de investigación de la profesora Dana Peters de la Escuela de Medicina de la Universidad de Yale. Mis proyectos consistieron en desarrollar herramientas automáticas para la evaluación de la función diastólica y para analizar el movimiento de la aurícula izquierda y la válvula mitral. Con esta experiencia logré descubrir mi mayor interés y definir cómo podía contribuir con la sociedad.

Pasantías de investigación realizadas en la Universidad de Yale, y en la Universidad de Alberta.
 Grupo de investigación de la profesora Dana Peters en la conferencia SCMR 2019.
Grupo de investigación de la profesora Dana Peters en la conferencia SCMR 2019.
4. ¿Cómo desarrollaste tu tesis en conjunto con dos universidades?
A medida que avanzaba con mi investigación en la Universidad de Yale, noté de forma vivencial que un proceso era muy repetitivo y manual: la segmentación de la aurícula izquierda. Recientemente, esta cavidad del corazón ha tenido un mayor interés de ser analizada cuantitativamente por imágenes de resonancia magnética por el valor que tiene en diagnosticar y pronosticar la fibrilación auricular, la arritmia cardíaca más frecuente. Para realizar este análisis, se requiere delinear esta cavidad (segmentar) en imágenes médicas para derivar su tamaño y su función a lo largo del ciclo cardíaco.
Viendo una clara oportunidad de mejora en el campo de la salud, decidí automatizar este proceso como parte de mi tesis. Entonces, presenté este proyecto al profesor Victor Murray, especialista en imágenes médicas de la UTEC, y gratamente aceptó supervisarme. Junto con el apoyo de la profesora Dana Peters, empecé a trabajar en mi tesis utilizando datos de pacientes de la Universidad de Yale. En el transcurso, en plenas conversaciones con sus colaboradores, el grupo del profesor Einar Heiberg de la Universidad de Lund, en Suecia, también me ofreció guiarme en el desarrollo de este proyecto con la oportunidad de implementar este método en su empresa médica enfocada al análisis de imágenes de resonancia magnética cardiovascular, Segment. Fue así cómo trabajé arduamente en este proyecto en tres países distintos, aprendiendo muchos temas en el camino, experimentando más a fondo el entorno académico, y también explorando nuevas culturas.
Me sentí muy privilegiado al ser asesorado por tres excelentes profesores. El profesor Victor Murray desde mis primeros ciclos me motivó a seguir la línea académica, me contó cómo era la vida en una escuela de posgrado y el campo de las imágenes médicas, y en la tesis, me brindó un apoyo excepcional, desde el marco pedagógico hasta los pequeños detalles técnicos. La profesora Dana Peters me recibió amablemente en su grupo, me invitó a los cursos que dictaba, me proponía proyectos muy didácticos con metas alcanzables, y me dio la oportunidad de regresar a la Universidad de Yale muchas veces. El profesor Einar Heiberg, a parte de mostrarme un notable desempeño académico mediante su ejemplo, me enseñó cómo un trabajo de investigación en este campo puede llegar a las manos de los médicos. Gracias a ellos y a sus grupos, logré finalizar este proyecto con una publicación en la revista BMC Medical Imaging. Por más que me sienta feliz con este resultado, guardo con mayor simbolismo este trayecto.
5. ¿Cuáles son tus próximos pasos?
Tras recibir esta formación excepcional, logré ser aceptado en un programa de doctorado en ciencias médicas de la Universidad de Oxford con una beca completa del Fondo Clarendon. Mi proyecto sigue una línea similar dentro de la resonancia magnética cardiovascular con un mayor enfoque en la caracterización de tejidos desarrollando procesos basados en datos. Luego, planeo mejorar el sistema del cuidado de la salud facilitándolo con herramientas tecnológicas. Haber llegado hasta aquí puede parecer un crecimiento lineal, pero sinceramente el proceso ha sido bastante turbulento, subsanado por una interminable lista de mentores por quienes estoy eternamente agradecido.